https://web.archive.org/web/20230902185655/https://en.everybodywiki.com/100_Most_Highly-Ranked_FilmsScrape Movies Table - Create Db
Case Study
You have been hired by a Multiplex management organization to extract the information of the top 50 movies with the best average rating from the web link shared below. You will use BeautifulSoup, save the data in CSV file as well as in sqlite3 db
- The information required is
Average Rank,Film, andYear - You are required to write a Python script
webscraping_movies.pythat extracts the information and saves it to aCSVfiletop_50_films.csv - You are also required to save the same information to a database
Movies.dbunder the table nameTop_50
Data
Libraries
pandaslibrary for data storage and manipulationBeautifulSouplibrary for interpreting theHTMLdocumentrequestslibrary to communicate with the web pagesqlite3for creating the database instance
library(reticulate)import requests
import sqlite3
import pandas as pd
from bs4 import BeautifulSoupVars
url = 'https://web.archive.org/web/20230902185655/https://en.everybodywiki.com/100_Most_Highly-Ranked_Films'
db_name = 'D:/data/Movies.db'
table_name = 'Top_50'
csv_path = 'D:/data/top_50_films.csv'
df = pd.DataFrame(columns=["Average Rank","Film","Year"])
count = 0.request Data
- To access the required information from the web page, you first need to load the entire web page as an
HTMLdocument inpythonusing therequests.get().textfunction and then - parse the text in the
HTMLformat usingBeautifulSoupto enable extraction of relevant information.
html_page = requests.get(url).text
data = BeautifulSoup(html_page, 'html.parser')Inspect Data
- Open the web page in a browser and locate the required table by scrolling down to it.
- Right-click the table and click
Inspectat the bottom of the menu, as shown in the image below
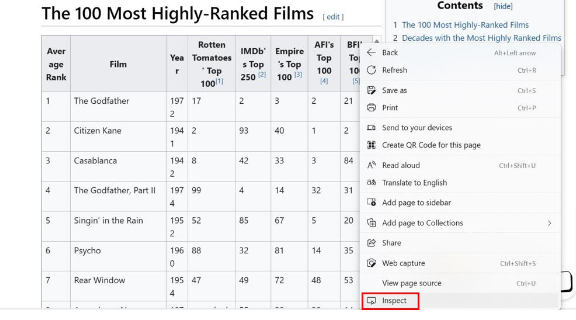
- This opens the
HTMLcode for the page and takes you directly to the point where the definition of the table begins. - To check, take your mouse pointer to the
tbodytag in theHTMLcode and see that the table is highlighted in the page section. - Notice that all rows under this table are mentioned as
trobjects under the table. - Clicking one of them would show that the data in each row is further saved as a
tdobject, as seen in the image above. - You require the information under the first three headers of this stored data.
- It is also important to note that this is the first table on the page. You must identify the required table when extracting information.
Extract/Scrape
find_all
- Write the loop to extract the appropriate information from the web page.
- The rows of the table needed can be accessed using the
find_all()function with theBeautifulSoupobject using the statements below
# Extract the body of all the tables into the tables var
tables = data.find_all('tbody')
# Extract all the tr tags from tables[0]= first table into the rows
rows = tables[0].find_all('tr')Iterate over rows
- Now we can iterate over every row and extract the required data
- Use the column[] to extract the content of each cell of the columns we are interested in
- Iterate over the contents of the variable
rows. - Check for the loop counter to restrict to 50 entries.
- Extract all the
tddata objects in the row and save them tocol. - Check if the length of
colis 0, that is, if there is no data in a current row. This is important since, many timesm there are merged rows that are not apparent in the web page appearance. - Create a dictionary
data_dictwith the keys same as the columns of the dataframe created for recording the output earlier and corresponding values from the first three headers of data. - Convert the dictionary to a dataframe and concatenate it with the existing one. This way, the data keeps getting appended to the dataframe with every iteration of the loop.
- Increment the loop counter.
- Once the counter hits 50, stop iterating over rows and break the loop.
- Print the df
for row in rows:
if count<50:
col = row.find_all('td')
if len(col)!=0:
data_dict = {"Average Rank": col[0].contents[0],
"Film": col[1].contents[0],
"Year": col[2].contents[0]}
df1 = pd.DataFrame(data_dict, index=[0])
df = pd.concat([df,df1], ignore_index=True)
count+=1
else:
break
print(df) Average Rank Film Year
0 1 The Godfather 1972
1 2 Citizen Kane 1941
2 3 Casablanca 1942
3 4 The Godfather, Part II 1974
4 5 Singin' in the Rain 1952
5 6 Psycho 1960
6 7 Rear Window 1954
7 8 Apocalypse Now 1979
8 9 2001: A Space Odyssey 1968
9 10 Seven Samurai 1954
10 11 Vertigo 1958
11 12 Sunset Blvd 1950
12 13 Modern Times 1936
13 14 Lawrence of Arabia 1962
14 15 North by Northwest 1959
15 16 Star Wars 1977
16 17 Parasite 2019
17 18 Schindler's List 1993
18 19 Lord of the Rings: The Fellowship of the Ring 2001
19 20 Shawshank Redemption 1994
20 21 It's a Wonderful Life 1946
21 22 Pulp Fiction 1994
22 23 Avengers: Endgame 2019
23 24 City Lights 1931
24 25 One Flew Over the Cuckoo's Nest 1975
25 26 Goodfellas 1990
26 27 Raiders of the Lost Ark 1981
27 28 12 Angry Men 1957
28 29 The Silence of the Lambs 1991
29 30 Taxi Driver 1976
30 31 Saving Private Ryan 1998
31 32 E.T. the Extra Terrestrial 1982
32 33 Alien 1979
33 34 Spider-Man: Into the Spider-verse 2018
34 35 Blade Runner 1982
35 36 Double Indemnity 1944
36 37 The Dark Knight 2008
37 38 The Wizard of Oz 1939
38 39 Star Wars: Episode V- The Empire Strikes Back 1980
39 40 The Searchers 1956
40 41 Mad Max: Fury Road 2015
41 42 Inception 2010
42 43 Lord of the Rings: Return of the King 2003
43 44 The Matrix 1999
44 45 Fight Club 1999
45 46 Back to the Future 1985
46 47 It Happened One Night 1934
47 48 The Good, the Bad, and the Ugly 1966
48 49 Lord of the Rings: The Two Towers 2002
49 50 All About Eve 1950Load
- Now the df has been created, save it to csv file
to_csv
df.to_csv(csv_path)Store in db
- To store the required data in a database, you first need to initialize a connection to the database,
- Save the dataframe as a table, and then
- Close the connection
- This database can now be used to retrieve the relevant information using SQL queries.
conn = sqlite3.connect(db_name)
df.to_sql(table_name, conn, if_exists='replace', index=False)50conn.close()Sample practice
Modify the code to extract
Film,Year, andRotten Tomatoes' Top 100headers.Restrict the results to only the top 25 entries.
Filter the output to print only the films released in the 2000s (year 2000 included).