library(tidyverse)
#_______________Let's create a function that reads our datain
getfile <- function(file){
fileDir <- setwd("D:/Education/R/Data/CompareCare/")
wantedFile = file.path(fileDir,file,fsep="/")
return(read.csv(wantedFile))
}
datain <- getfile("outcome-of-care-measures.csv")CompareCare
This document is part of a long, detailed, real business case that took months to complete. My analysis and recommendations led to the creation of a care comparison mobile application months after the release of the data. The information I gathered from this study opened my eyes to many hidden procedures, that the industry wanted to remain buried, and still are. As the healthcare industry took many sharp turns since the release of this data, it’s only the tip of what we’ll never know about the inner workings of our healthcare industry.
This wasn’t the first time for me in the healthcare domain, as I was lead analyst for a complete build of an EHR system for a large hospital in the Midwest, long before the government demanded that all hospitals implement the technology.
Years after these two projects, I was lead analyst for another privately funded EHR dedicated solely for the Homeless population.
Code Explanation
The first part of this document is geared towards case studies and results. For coding, analysis details and step by step instructions, I saved it all for the last section of this document titled RANK ALL STATES. Please, review that section at the bottom of this document for all the details.
Government Background
The Centers for Medicare & Medicaid Services (CMS) and the nation’s hospitals work collaboratively to publicly report hospital quality performance information on Care Compare on Medicare.gov and the Provider Data Catalog.
Hospital Care Compare displays hospital performance data in a consistent, unified manner to ensure the availability of credible information about the care delivered in the nation’s hospitals. The hospitals displayed on Care Compare are generally limited to Acute Care Hospitals, Acute Care Veteran’s Hospitals, Department of Defense Hospitals, Critical Access Hospitals, and Children’s Hospitals. Only data from Medicare-certified hospitals are included on Care Compare. Most of the participants are short-term acute care hospitals that will receive a reduction to the annual update of their Medicare fee-for-service payment rate if they do not participate by submitting data or meet other requirements of the Hospital Inpatient Quality Reporting (IQR) Program and the Hospital Outpatient Reporting (OQR) Program. The Hospital IQR Program was established by Section 501(b) of the Medicare Modernization Act of 2003 and extended and expanded by Section 5001(a) of the Deficit Reduction Act of 2005. The Hospital OQR Program was mandated by the Tax Relief and Health Care Act of 2006.
Finally, in the early 2010’s the president ordered the government to release the data (that has been collected for over a decade) to the public. That’s when my employer requested, I review the data and provide a business plan for the company to capitalize on the information.
As part of any project, it is extremely important to document every little detail so everyone can understand how we arrived at the final answer.
What follows is a quick walk through several case studies leading to a very detailed breakdown in the final case study. Sort of a “lesson learned” document so anyone reviewing the code will follow my train of thought and can easily retrace and duplicate the steps.
I’ve omitted all the work I did using SQL and duplicated it with R.
Import Data
The data was downloaded as a large zip file which contained hundreds of .csv files going back for over 10 years. The file was downloaded locally and then the process started.
A pdf file is provided to explain the meaning of all the codes along with hundreds of pages of other valuable definitions.
EDA - Mortality Rates
Since we’re inspecting the data let’s take a quick look at some of the mortality rates for all hospitals across one condition, just to get an idea of how the values are spread. I’ll do that by plotting a quick histogram of the mortality rates for “heart attacks”. I’m curious as to how wide the data varies across states and outcome.
datain[,11] <- as.numeric(datain[,11])
hist(datain[,11])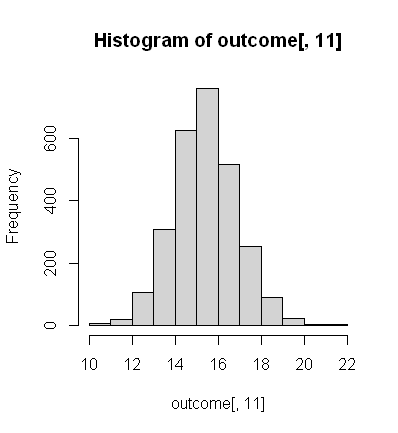
Observations
I didn’t expect the rate to vary by 10% (or double) across hospitals. It might not sound like much for the rates to vary by 10% but when that’s double the rate it does raise my curiosity level. This has become extremely interesting; I wonder if there will be a correlation between the extremes.
Best in State
Now that I have an idea of what these rates look like, let’s:
- Write a function(best) that accepts 2 arguments: 2 char abbreviated state name, and an outcome name; in order to
- Find the best hospital in each state, names can be found in column 2 – Hospital.Name
- Mortality rates are tracked in Column 11 – Hospital.30.Day.Death..Mortality..Rates.from.Heart.Attack
- Column 17 – Hospital.30.Day.Death..Mortality..Rates.from.Heart.Failure
- Column 23 – Hospital.30.Day.Death..Mortality..Rates.from.Pneumonia
- Hospitals with no data on that specific outcome should be excluded from that set
- If a tie exists in that set, then sort Hospital names in alphabetical order and the first on that list will be the winner of the tie
- If an invalid state is passed, function should throw an error via the stop function “invalid state”. Column 7 – State
- If an invalid outcome is passed to best, function should throw an error via the stop function “invalid outcome”
Create best Function
- Write a function(best) that accepts 2 arguments: 2 char abbreviated state name, and an outcome name; in order to
- Find the best hospital in each state based on 30-day mortality rate (lowest)
- Base it on Columns 11 (heart attack), 17 (heart failure), 23 (pneumonia)
- Hospitals with no data on that specific outcome should be excluded from that set
- If a tie exists in that set, then sort in alphabetical order and the first on that list will be the winner
- If an invalid state is passed to best, function should throw an error via the stop function “invalid state”
- If an invalid outcome is passed to best, function should throw an error via the stop function “invalid outcome”
# _____________________ CREATE THE FUNCTION THAT FINDS THE BEST HOSPITAL
best <- function(state, outcome) {
#read data in using the function getfile()
datain <- getfile("outcome-of-care-measures.csv")
## Check that state and outcome are valid
if (!(state %in% datain[,7]))
{ stop("invalid state")}
if (!((outcome == "heart attack") |
(outcome == "heart failure") |
(outcome == "pneumonia")))
{stop("invalid outcome")}
# Create a subset for the only state given by the user
# we could use stateonly <- filter(datain, State == state)
# note state is the argument passed into the function
stateonly <- subset(datain, State == state)
# Assign outcome to appropriate column so we can filter that out
if (outcome == "heart attack") {usethis = 11}
if (outcome == "heart failure") {usethis = 17}
if (outcome == "pneumonia") {usethis = 23}
# Let's filter the stateonly subset to include Hospital Name, and the outcome given by user
subdata <- select(stateonly, c("State", "Hospital.Name", all_of(usethis)))
# Not Applicable in the 3rd column is not detected by any of the NA functions so I'll do it manually
gooddata <- subset(subdata, subdata[3] != "Not Available")
#rate in df is a char, so unlist it and coerce it to a numeric
gooddata[3] <- as.numeric(unlist(gooddata[3]))
# Arrange in ascending order of rate=col[3] first and name=col[2] second to break a tie if it exists
#and assign the row number to the new rank column
blah <- gooddata |>
arrange((gooddata[3]), gooddata[2]) |>
mutate(rank = row_number())
#return the hospital name with the lowest rank or row 1 col 2
blah <- (blah[1,2])
}Best Test
# _____________________ TEST BEST in STATE FUNCTION
best("TX", "heart attack")
[1] "CYPRESS FAIRBANKS MEDICAL CENTER"
best("TX", "heart failure")
[1] "FORT DUNCAN MEDICAL CENTER"
best("MD", "heart attack")
[1] "JOHNS HOPKINS HOSPITAL, THE"
best("MD", "pneumonia")
[1] "GREATER BALTIMORE MEDICAL CENTER"
best("BB", "heart attack")
Error in best("BB", "heart attack") : invalid state
best("NY", "hert attack")
Error in best("NY", "hert attack") : invalid outcome
best("SC", "heart attack")
[1] "MUSC MEDICAL CENTER"
best("AK", "pneumonia")
[1] "YUKON KUSKOKWIM DELTA REG HOSPITAL"Rank by State
Continuing with our exploratory analysis, let’s create a function that returns the hospital for a ranking that we provide, in the state we provide, and for the mortality rate that we provide. For example, let’s say the user wants to know which hospital(s) ranked as top 3, or worst 6 for heart failure in the state of TX?
Create rankhospital Function
- The function rankhospital() will take 3 arguments: State, outcome, rank
- This time we want to pull that specific hospital that meets that rank for that specific outcome
- Just as before if state or outcome are invalid execute a stop() with message
- Rank argument accepts “best”, “worst”, or an integer indicating the desired rank, the lower the number the better the rank
- If rank argument is greater than the ranks for the outcome, return NA
- As before, a tie is decided by the alphabetical order of hospitals
- Output is a character vector of the hospital name meeting the conditionThe function rankhospital() will take 3 arguments: State, outcome, rank
- This time we want to pull that specific hospital that meets that rank for that specific outcome
- Just as before if state or outcome are invalid execute a stop() with message
- Rank argument accepts “best”, “worst”, or an integer indicating the desired rank, the lower the number the better the rank
- If rank argument is greater than the ranks for the outcome, return NA
- As before, a tie is decided by the alphabetical order of hospitals
- Output is a character vector of the hospital name meeting the condition
#______________Function to return hospital with the desired ranking based on outcome
rankhospital <- function(state, outcome, num = "best") {
#read data in using the function getfile()
datain <- getfile("outcome-of-care-measures.csv")
## Check that state and outcome are valid
if (!(state %in% datain[,7]))
{ stop("invalid state")}
if (!((outcome == "heart attack") |
(outcome == "heart failure") |
(outcome == "pneumonia")))
{stop("invalid outcome")}
# Create a subset for the only state given by the user
# we could use stateonly <- filter(datain, State == state)
# note state is the argument passed into the function
stateonly <- subset(datain, State == state)
# Assign outcome to appropriate column so we can filter that out
if (outcome == "heart attack") {usethis = 11}
if (outcome == "heart failure") {usethis = 17}
if (outcome == "pneumonia") {usethis = 23}
# Filter stateonly subset to include Hospital Name & outcome given by user
subdata <- select(stateonly, c("State", "Hospital.Name", all_of(usethis)))
# Not Applicable in the 3rd column is not detected by any of the NA functions
# so do it manually
gooddata <- subset(subdata, subdata[3] != "Not Available")
#now that we've removed empty rows we can test num input and set variables
if (num == "best") {num = 1}
if (num == "worst") {num = nrow(gooddata)}
#rate in df is a char, so unlist it and coerce it to a numeric
gooddata[3] <- as.numeric(unlist(gooddata[3]))
# Arrange in ascending order of rate=col[3] first and
# name=col[2] second to break a tie if it exists
# Create rank and create new col
blah <- gooddata |>
arrange((gooddata[3]), gooddata[2]) |>
mutate(rank = row_number())
#return the hospital name with the desired rank
if (num > nrow(gooddata))
{ blah = "NA"}
else
{blah <- (blah[num,2])}
}Rankhospital Test
# _________________________ TEST RANKHOSPITAL
rankhospital("TX", "heart attack", 1)
[1] "CYPRESS FAIRBANKS MEDICAL CENTER"
rankhospital("TX", "heart attack", "best")
[1] "CYPRESS FAIRBANKS MEDICAL CENTER"
rankhospital("TX", "heart attack", 102)
[1] "LONGVIEW REGIONAL MEDICAL CENTER"
rankhospital("TX", "heart attack", "worst")
[1] "LAREDO MEDICAL CENTER"
rankhospital("TX", "heart attack", 2000)
[1] "NA"
rankhospital("TX", "heart failure", 4)
[1] "DETAR HOSPITAL NAVARRO"
rankhospital("MD", "heart attack", "worst")
[1] "HARFORD MEMORIAL HOSPITAL"
rankhospital("NC", "heart attack", "worst")
[1] "WAYNE MEMORIAL HOSPITAL"Rank All States
Ok, so let’s back up a bit. Let’s say the user wants to know which state has the best rates for each outcome. Let’s say we want to narrow down the states with the best mortality rates for heart attacks. Or maybe the worst states for pneumonia?
Create rankall Functions
- Takes 2 args: (outcome) and hospital ranking (num)
- Outcome is identical to what we used before
- (num)
- Output is a 2 column df containing the hospital in each state that satisfies the rank=num specified by user
- First column is named: (hospital) and second is (state) containing 2-char abbreviation
- As before if a hospital doesn’t have data for that outcome it should be excluded
- num just as before could be “bet”, “worst”, an integer within the range or out of range of the ranks
- Some states might have NA values as no hospital might meet the ranking requirements, it’s ok. This part could be tricky if you misread it. To deal with it:
- I’ll create a list of all states in the dataset
- Once user enters a num, and the dataset is filtered to that value, I’ll compare this subset to the list of all states and enter NA for any rows in the list of all states that are not in the new subset (filtered) dataset
- Ranking ties are handled as before
- Input validity is as before
library(tidyverse)
#_______________Let's copy the function from before, that reads our datain
getfile <- function(file){
fileDir <- setwd("D:/~/")
wantedFile = file.path(fileDir,file,fsep="/")
return(read.csv(wantedFile))
}
datain <- getfile("outcome-of-care-measures.csv")
#______________Function to return the hospital with the desired ranking based on outcome
rankall <- function(outcome, num = "best") {
# check validity of (outcome input)
if (!((outcome == "heart attack") |
(outcome == "heart failure") |
(outcome == "pneumonia")))
{stop("invalid outcome")}
# Assign outcome to appropriate column so we can filter that out
if (outcome == "heart attack") {usethis = 11}
if (outcome == "heart failure") {usethis = 17}
if (outcome == "pneumonia") {usethis = 23}
# Let's filter out columns not needed
subdata <- select(datain, c("State", "Hospital.Name", all_of(usethis)))
# Not Applicable in the 3rd column is not detected by any of the NA functions so
# do it manually
gooddata <- subset(subdata, subdata[3] != "Not Available")
# rate in df is a char, so unlist it and coerce it to a numeric
gooddata[3] <- as.numeric(unlist(gooddata[3]))
# Let's group by state add count for each state group (found)
groudata <- gooddata |>
group_by(gooddata$State) |>
mutate(found = n())
# Sort in ascending order, and add (rank) col for each row in the group
bystate <- groudata |>
arrange((groudata[3]), groudata[2], .by_group = TRUE) |>
mutate(rank = row_number())
# now that we've removed empty rows we can test num input and set variables
if (num == "best") {num = 1}
if (num == "worst") {num = bystate$found}
# filter bystate to show rows with rank = input
rankedout <- subset(bystate, bystate$rank == num)
# create a list of all states and their count/found
statesfound <- bystate[,c("State","Hospital.Name","found")]
# because source df has duplicates, so eliminate duplicates
statesfound <- statesfound[!duplicated(statesfound$State),]
# If user inputs num>found (values) for a state, display NA
# outlist <- statesfound
# outlist$Hospital.Name[outlist$found < num] <- "NA"
# bring hospital names from statesfound for other states with value
almostlist <- merge(statesfound, rankedout, by= "State", all.x = TRUE)
# Because both df statesfound and rankedout have a col Hospital.Name then
# the merged(wanted) one is labeled ~.y
outlist <- almostlist[c("State","Hospital.Name.y")]
outlist <- outlist |>
rename(Hospital = Hospital.Name.y)
return(outlist)
}Rankall Test
outlist <- rankall("pneumonia",20)
head(outlist,10)
OUTPUT
State Hospital
1 AK <NA>
2 AL CHILTON MEDICAL CENTER
3 AR BAPTIST HEALTH MEDICAL CENTER HEBER SPINGS
4 AZ SCOTTSDALE HEALTHCARE-SHEA MEDICAL CENTER
5 CA FOUNTAIN VALLEY REGIONAL HOSPITAL & MEDICAL CENTER
6 CO VALLEY VIEW HOSPITAL ASSOCIATION
7 CT MIDSTATE MEDICAL CENTER
8 DC <NA>
9 DE <NA>
10 FL KENDALL REGIONAL MEDICAL CENTER
outlist <- rankall("pneumonia","worst")
tail(outlist,3)
OUTPUT
State Hospital
52 WI MAYO CLINIC HEALTH SYSTEM - NORTHLAND, INC
53 WV PLATEAU MEDICAL CENTER
54 WY NORTH BIG HORN HOSPITAL DISTRICT
outlist <- rankall("heart failure")
tail(outlist,10)
OUTPUT
State Hospital
45 TN WELLMONT HAWKINS COUNTY MEMORIAL HOSPITAL
46 TX FORT DUNCAN MEDICAL CENTER
47 UT VA SALT LAKE CITY HEALTHCARE - GEORGE E. WAHLEN VA MEDICAL CENTER
48 VA SENTARA POTOMAC HOSPITAL
49 VI GOV JUAN F LUIS HOSPITAL & MEDICAL CTR
50 VT SPRINGFIELD HOSPITAL
51 WA HARBORVIEW MEDICAL CENTER
52 WI AURORA ST LUKES MEDICAL CENTER
53 WV FAIRMONT GENERAL HOSPITAL
54 WY CHEYENNE VA MEDICAL CENTER